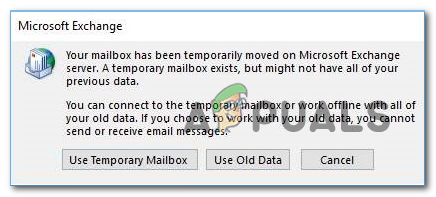
Google Pixel 5?
Google tiene anunció la disponibilidad de múltiples conjuntos de datos compuesto por imágenes naturales diversas pero limitadas. El gigante de las búsquedas confía en que los datos disponibles públicamente impulsarán el ritmo de Aprendizaje automático e inteligencia artificial mientras se reduce el tiempo necesario para entrenar los modelos de IA con una cantidad mínima de datos. Google llama a la nueva iniciativa 'Metadatos de datos gratuitos' que ayudarán a los modelos de IA a 'aprender' con menos datos. La 'IA de pocos disparos' de la empresa está optimizada para garantizar que la IA aprenda nuevas clases a partir de unas pocas imágenes representativas.
Al comprender la necesidad de entrenar rápidamente modelos de inteligencia artificial y aprendizaje automático con menos conjuntos de datos, Google ha lanzado 'Meta-Dataset', una pequeña colección de imágenes que debería ayudar a reducir la cantidad de datos necesarios para mejorar la precisión de los algoritmos. La compañía afirma que al usar técnicas de clasificación de imágenes de pocas tomas, los modelos de IA y ML obtendrán los mismos conocimientos a partir de muchas menos imágenes representativas.
Google AI anuncia metadatos: un conjunto de datos para el aprendizaje de pocas oportunidades:
El Deep Learning para IA y Machine Learning ha estado creciendo exponencialmente durante bastante tiempo. Sin embargo, el requisito principal es la disponibilidad de datos de alta calidad y también en grandes cantidades. Las grandes cantidades de datos de entrenamiento anotados manualmente a menudo son difíciles de obtener y, a veces, tampoco pueden ser confiables. Al comprender los riesgos de los grandes conjuntos de datos, Google ha anunciado la disponibilidad de una colección de metadatos.
Mediante ' Meta-Dataset: un conjunto de datos de conjuntos de datos para aprender a aprender de unos pocos ejemplos '(Presentado en ICLR 2020 ), Google ha propuesto un punto de referencia diverso y a gran escala para medir la competencia de diferentes modelos de clasificación de imágenes en un entorno realista y desafiante de pocas tomas, ofreciendo un marco en el que se pueden investigar varios aspectos importantes de la clasificación de pocas tomas. Básicamente, Google ofrece 10 conjuntos de datos de imágenes naturales disponibles públicamente y de uso gratuito. Estos conjuntos de datos comprenden ImageNet, CUB-200-2011, Fungi, caracteres escritos a mano y garabatos. El codigo es público e incluye un cuaderno que demuestra cómo se pueden utilizar los metadatos en TensorFlow y PyTorch .
La clasificación de pocos disparos va más allá de la modelos estándar de formación y aprendizaje profundo . Lleva la generalización a clases completamente nuevas en el momento del examen. En otras palabras, las imágenes utilizadas durante las pruebas no se vieron en el entrenamiento. En una clasificación de pocos disparos, el conjunto de entrenamiento contiene clases que son completamente distintas de las que aparecerán en el momento de la prueba. Cada tarea de prueba contiene un conjunto de soporte de unas pocas imágenes etiquetadas de las que el modelo puede aprender sobre las nuevas clases y una conjunto de consultas de ejemplos que luego se pide al modelo que clasifique.
Un metadato es un componente grande en el que el modelo estudia la generalización a conjuntos de datos completamente nuevos , del cual no se vieron imágenes de ninguna clase en el entrenamiento. Esto se suma al difícil desafío de generalización para nuevas clases inherente a la configuración de aprendizaje de pocas oportunidades.
¿Cómo ayudan los metadatos al aprendizaje profundo para modelos de inteligencia artificial y aprendizaje automático?
Meta-Dataset representa el punto de referencia organizado a mayor escala para la clasificación de imágenes de pocos disparos de conjuntos de datos cruzados hasta la fecha. También introduce un algoritmo de muestreo para generar tareas de diferentes características y dificultad, variando el número de clases en cada tarea, el número de ejemplos disponibles por clase, introduciendo desequilibrios de clases y, para algunos conjuntos de datos, variando el grado de similitud entre los clases de cada tarea.
Meta-Dataset introduce nuevos desafíos para una clasificación de pocos disparos. La investigación de Google aún es preliminar y hay mucho terreno por recorrer. Sin embargo, el gigante de las búsquedas ha afirmado que los investigadores están teniendo éxito. Algunos de los ejemplos notables incluyen el uso de tarea acondicionamiento , más sofisticado ajuste de hiperparámetros , a ‘ meta-línea de base ’Que combina los beneficios de la formación previa y el metaaprendizaje y, finalmente, utiliza selección de características especializar una representación universal para cada tarea.
Etiquetas google